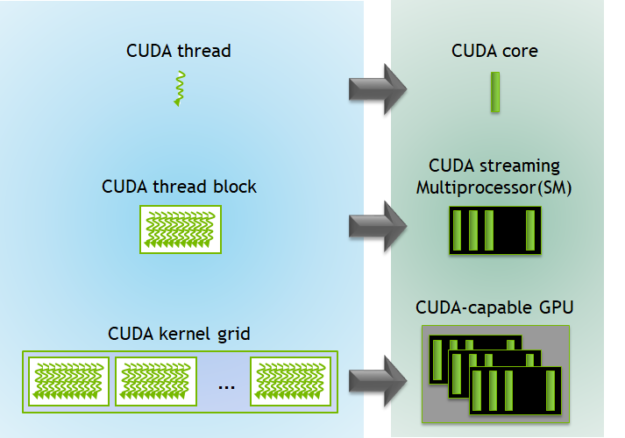
CUDA Kernel Execution
CUDA Kernel Execution
- A group of threads is called a CUDA block
- CUDA blocks are grouped into a grid
- A kernel is executed as a grid of blocks of threads
- Each CUDA block is executed by one streaming multiprocessor (SM) and caannot be migrated to other SMs in GPU.
- One SM can run multiple CUDA blocks concurrently
- Each kernel is executed on one device and CUDA supports multiple kernels on a device at one time
Divide and Conquer
- CPU binary search code in c++ ```cpp #include <bits/stdc++.h> using namespace std;
// A recursive binary search function. It returns location of x in given array, otherwise -1 int binarySearch(int arr[], int l, int r, int x) { if (r >= l) { int mid = l + (r - l) / 2; if (arr[mid] == x) return mid; if (arr[mid] > x) return binarySearch(arr, l, mid - 1, x); return binarySearch(arr, mid + 1, r, x); } return -1; }
int main(void) { int arr[] = { 2, 3, 4, 10, 40 }; int x = 10; int n = sizeof(arr) / sizeof(arr[0]); int result = binarySearch(arr, 0, n - 1, x); (result == -1) ? cout « “Element is not present in array” : cout « “Element is present at index “ « result; return 0; }
2. Distributed Search in CUDA
```cpp
__global__ void search(const float *input, const int x, int *index) {
if(input[threadIdx.x] == x) *index = threadIdx.x;
}
int main() {
const int N = 256000;
float *h_data[N];
int index = -1;
int x = rand() % N;
for (int i = 0; i < N; i++) h_data[i] = i;
float *d_data[N];
int *d_i;
cudaMalloc((void **) &d_data, N*sizeof(int));
cudaMalloc((void **) &d_i, sizeof(int);
cudaMemcpy(&h_data, d_data, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(&index, d_i, sizeof(int), cudaMemcpyHostToDevice);
search<<<1, 1>>> (d_data, x, d_i);
cudaMemcpy(&index, d_i, sizeof(int), cudaMemcpyDeviceToHost);
}
- Merge Sort ```cpp void merge(int arr[], int p, int q, int r) { // Create L ← A[p..q] and M ← A[q+1..r] int n1 = q - p + 1; int n2 = r - q; int L[n1], M[n2]; for (int i = 0; i < n1; i++) L[i] = arr[p + i]; for (int j = 0; j < n2; j++) M[j] = arr[q + 1 + j]; // Maintain current index of sub-arrays and main array int i, j, k; i = 0; j = 0; k = p; // Until we reach either end of either L or M, pick larger among // elements L and M and place them in the correct position at A[p..r] while (i < n1 && j < n2) { if (L[i] <= M[j]) { arr[k] = L[i]; i++; } else { arr[k] = M[j]; j++; } k++; } while (i < n1) { arr[k] = L[i]; i++; k++; } while (j < n2) { arr[k] = M[j]; j++; k++; } }
// Divide the array into two subarrays, sort them and merge them void mergeSort(int arr[], int l, int r) { if (l < r) { // m is the point where the array is divided into two subarrays int m = l + (r - l) / 2;
mergeSort(arr, l, m);
mergeSort(arr, m + 1, r);
// Merge the sorted subarrays
merge(arr, l, m, r);
} } ``` 4. CUDA merge sort ```cpp __device__ void gpu_bottomUpMerge(long* source, long* dest, long start,
long middle, long end) {
long i = start;
long j = middle;
for (long k = start; k < end; k++) {
if (i < middle && (j >= end || source[i] < source[j])) {
dest[k] = source[i];
i++;
} else {
dest[k] = source[j];
j++;
} } }
global void gpu_mergesort(long* source, long* dest, long size, long width, long slices, dim3* threads, dim3* blocks) { unsigned int idx = threadIdx.x + threadIdx.y * (x = threads->x) + threadIdx.z * (x *= threads->y) + blockIdx.x * (x *= threads->z) + blockIdx.y * (x *= blocks->z) + blockIdx.z * (x *= blocks->y); long start = width * idx *slices, middle, end; for (long slice = 0; slice < slices; slice++) { if (start >= size) break; middle = min(start + (width » 1), size); end = min(start + width, size); gpu_bottomUpMerge(source, dest, start, middle, end); start += width; } }
### Defining Kernel Thread and Data Layout via Blocks
1. 1-Dimensional Layout: `kernel<<<blocks, threads_per_block>>>(params)`
```cpp
#define N 1618
add <<<1, 32>>>(a, b, c);
__global__ add(int *a, int *b, int *c) {
// 1 1 x(from 0 to 32)
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
c[idx] = a[idx] + b[idx];
}
}
- 2-Dimensional Layout:
kernel<<< grid, block>>>(parameters)```cpp #define N 512 dim3 grid(1, 1); // grid = 1 x 1 2D arrary of blocks dim3 block(32, 32); // block = 32 x 32 2D array of threads matrixMult«<grid, block»>(matrix_a, matrix_b, output_matrix);
global matrixMult(int *matrix_a, int * matrix_b, int * c) { int x = blockIdx.x * blockDim.x + threadidx.x; int y = blockIdx.y * blockDim.y + threadidx.y; int index = x + y * N; // index to the thread if (x < N && y < N) { c[index] = a[index] * b[index]; } }
3. 3-Dimensional Layout: `kernel<<< grid, block>>>(parameters)`
```cpp
#define N 16
dim3 grid(1, 1, 1); // grid = 1 x 1 x 1 3D arrary of blocks
dim3 block(N, N, N); // block = 32 x 32 x 32 3D array of threads
matrixSubtract<<<grid, block>>>(matrix_a, matrix_b, output_matrix);
__global__ matrixSubtract(int *matrix_a, int * matrix_b, int * c) {
// 1
int x = blockIdx.x * blockDim.x * blockDim.y * blockDim.z // offset in general
+ threadIdx.z * blockDim.y * blockDim.x // offset for z
+ threadIdx.y * blockDim.x // offset for y
+ threadIdx.x; // offset for x
if (index < N * N * N> {
c[index] = a[index] - b[index];
}
}
Threads, Blocks and Grids
- 1D Threads , Blocks & Grid ```cpp #define N 512 dim3 grid(32, 32); // grid = 32 x 32 2D arrary of blocks dim3 block(1, 1); // block = 1 x 1 2D array of threads matrixAdd«<grid, block»>(matrix_a, matrix_b, output_matrix);
global matrixMult(int *matrix_a, int * matrix_b, int * c) { int blockId = blockIdx.x + blockIdx.y * gridDim.x; int threadId = threadIdx.x + blockId * blockDim.x; if (threadId < 512) { c[threadId] = a[threadId] + b[threadId]; } }
2. 2D Threads , Blocks & Grid
```cpp
#define N 2048
dim3 grid(1, 1); // grid = 1 x 1 2D arrary of blocks
dim3 block(32, 32); // block = 32 x 32 2D array of threads
matrixDiff<<<grid, block>>>(matrix_a, matrix_b, output_matrix);
__global__ matrixDiff(int *matrix_a, int * matrix_b, int * c) {
int blockId = blockIdx.x + blockIdx.y * gridDim.x;
int threadId = threadIdx.x
+ threadIdx.y * blockDim.x
+ blockId * blockDim.x * blockDim.y;
c[index] = a[index] - b[index];
}
- 3D Threads, Blocks & Grid
#define N 32768
dim3 grid(2, 2, 2); // grid = 2 x 2 x 2 3D arrary of blocks
dim3 block(16, 16, 16); // block = 16 x 16 x 16 3D array of threads
matrixMod<<<grid, block>>>(matrix_a, matrix_b, output_matrix);
__global__ matrixMod(int *matrix_a, int * matrix_b, int * c) {
int blockId = blockIdx.x
+ blockIdx.y * gridDim.x
+ blockIdx.z * gridDim.x * gridDim.y;
int threadId = threadIdx.x
+ threadIdx.y * blockDim.x
+ threadIdx.z * blockDim.x * blockDim.y
+ blockId * blockDim.x * blockDim.y * blockDim.z;
c[index] = a[index] % b[index];
}
Nvidia GPU Device Global Memory
GDDR -> HBM, 2GB from 2008 to 24 GB in 2020
- Titan Xp (Pascal)
- 3840 cuda cores
- 12 GB GDDR5 Memory
- 384 bit bandwidth
- 1405 MHz clock
- SM count: 30
- L1 Cache: 48KB per SM
- L2 Cache: 3MB
- CUDA: 6.1
- FLOPS: FP32: 12.15 TFLOPS, FP64: 379.7 GFLOPS
- Titan RTX (Turning)
- 4608 cuda cores
- 24 GB GDDR6 Memory
- 384 bit bandwidth
- 1350 MHz clock
- SM count: 72
- L1 Cache: 64KB per SM
- L2 Cache: 6MB
- CUDA: 7.5
- FLOPS: FP32: 16.31 TFLOPS, FP64: 509.8 GFLOPS
Nvidia GPU Global Memory Analysis
- nvidia-smi
- -L: list GPUs
- -i=id1,id2: filter the GPU to the specified list of devices
- -q: query devices information
- -d=TYPE: filter the -q information to the specified type, eg MEMORY etc
- https://www.techpowerup.com/gpu-specs/
Host Memory Allocation

- Host Memory Primitive Allocation
- int a; float b;
- Host Pageable Memory Pointers Allocation
int *a = (int*)malloc(1024 * sizeof(int));
- Host Non-pageable Memory Pointers Allocation
- Pinned memory allocation (removes extra host-side memory transfers):
float *a = cudaMallocHost((float**)&a, 1024 * sizeof(float)); - Mapped memory allocation (no copies to device memory):
float *a = cudaMallocHost((float**)&a, 1024 * sizeof(float), cudaHostAllocMapped); - Unified memory allocation (no need to worry about copies let system do it for you):
float *a = cudaMallocManaged((float**)&a, 1024 * sizeof(float));Device Memory Allocation
- Pinned memory allocation (removes extra host-side memory transfers):
- Device Memory cudaMalloc
__host__ __device__ cudaError_t cudaMalloc(void**devPtr, size_t, size)- allocates memory to pointer of specified size
- allocate primitive:
int dev_a; cudaMalloc(&dev_a, sizeof(int)); - allocate array:
int *dev_a; cudaMalloc(&dev_a, 1024 * sizeof(int));
- Device cudaMemcpy Command
- Pageable/Pinned Memory copy (to/from device memory):
cudaMemcpy(input_a, dev_a, cudaMemcpyHostToDevice);
cudaMemcpy(dev_a, input_a, cudaMemcpyDeviceToHost); - Mapped Memory device memory allocation/copy
cudaHostGetDevicePointer((int**)&dev_a, (int*)input_a, 1024 * sizeof(int)); - Unified memory device is allocated on the host, so no memory copy, just pass pointer to kernel.
Nvidia GPU Shared and Constant Memory Hardware
L1 Cache is shared within each SMs. L2 Cache is shared among SMs.
Nvidia GPU Shared and Constant Memory Analysis
use
nvidia-smicommand or online lookup the number for the GPU at hand.Nvidia Shared Memory Allocation
- Pageable/Pinned Memory copy (to/from device memory):
- Device Shared Memory Allocation Syntax
- Shared memory is done inside the kernel, since threads in a block share L1 cache.
- If the size of the shared memory is known at compile time(e.g. number of elements in an array), then a static syntax is used.
__shared__ data_type array_name[number of elements] - If the size of the shared memory is no known at compile time(e.g. conditional branching after initialization), then a dynamic usage pattern is used. ```cpp extern shared data_type array_name[]
float dynamic_float_data = x; // defined within the kernel char *firstName = (char)&firstName[number letters in given name];
2. Device Race Condition Avoidance
+ Shared memory is fater than global memory, shared within threads in a block
+ it can happen that memory is access in real time in an interleaved manner, with different threads read or write before / after each other.
+ to deal with this, you need to synchronize the threads `__synchthreads();`
### Nvidia Constant Memory Allocation
1. Device Constant Memory
+ Constant memory is memory that is read-only
+ Always maxed at 64KB
+ It is globally accessible on the devicve, to all thread simultaneously
+ It can be faster than global memory and as fast as register memory as long as there are no read misses
+ A lot of the performance is based around half warps (16 threads per 1/2 warp), so branching can also have an effect on how efficient this is.
2. Device Constant Memory Syntax
+ Declaration: `__constant__ data_type array_name[number of elements]`
+ Copy host data to constant memory
```cpp
cudaError t cudaMemcpytoSymbol(const data_type * symbol_name, void *src_ptr, size_t size, size_t offset, enum cudaMemcpyKind);
err = cudaMemcpyToSymbol(c_a, h_a, size, 0, cudaMemcpyHostToDevice);
Nvidia GPU Register Memory
- Register Memory Usage
- All variables are allocated as register memory
- It is possible to allocate more thread local memory than is available
- When memory is allocated beyond register memory, CUDA will need to read/write data to/from cache memory.
- So you probably have already been using register memory without even knowing it.
Nvidia GPU Register Memory Analysis
use
nvidia-smicommand or online lookup the number for the GPU at hand.Nvidia GPU Memory Comparison
- Memory Type Use Cases
- Global Memory: 24 GB
- all non-constant data goes through global memory, this will limit size of all input data to GPU.
- all threads have same access + Constant Memory: 64KB with 8KB cache
- Broadcast data to all threads, predefined kernels, etc
- slow as global memory and value can not change + Shared Memory: 192KB
- When threads in a block need to communicate, small window of data required for threads within a block, share intermediary results + Register Memory: 64KB
- Thread-safe memory which can be used to store data from other types of memory to avoid incoherence for non-local data