Concurrent Programming with Modern CPUs
Concurrent Programming with Modern CPUs
- The state of single computation process that takes multiple cycles can be managed as a thread.
- Scheduling algorithms shifts threads between inactive and active states.
- Memory caching is used to shift thread state memory between hard drive and various form of solid state memory such as RAM and registers.
Pitfalls in Concurrent Programming
- Race Conditions
- When the expected order of thread opeartionsis not followed and issues arise
- Resource Contention
- Two or more threads attempt to access/modify the same memory and conflict
- Dead Lock
- One or more processes are blocked from making progress while waiting for resource
- Live Lock
- like dead lock but processes are activly running
- Resource Over / Under Utilization
- Too little work, CPUs are thus sitting idle
- Too many threads, CPUs are spending too much time context switching
- Processes are overly complex and therefor CPU may be overextending itself
- Memory required for processes is too large or changes too frequently
Concurrent Programming Problems and Algorithms
- Dining Philosophers
- Each philosopher has a fork on their left and right
- They want to eat eggs and side dish
- To eat, each philosopher needs both foks.
- We need an algorithm that allows all philosophers to eat
- Producer-Consumer
- One or more consumers need to read data in order and without duplication
- One or more producers add data in the order that it needs to be processed
- It is easy to produce race conditions when trying to solve this problem
- Sleeping Barber
- N customers can sit in the waiting room
- There is only 1 barber
- When inactive the barber sleeps
- If the barber is sleeping a customer should wake him up and sleep
- If there is no space in the waiting room, a customer leaves
- Data and code Synchronization
Concurrent Programming Patterns
- Divide and Conquer
- Take large datasets and divide up
- Often implemented via recursive algorithms
- Solving small problems and apply those solutions to solve larger problems
- Easily implemented on powerful computing platforms that can maintain complex state
- Map-Reduce
- Similar to divide and conquer, with division of data/computation
- Often skips much of hierarchy of divide and conquer, map single data point to a single result
- Reduce series of inputs to single result
- Can include multiple stages and repeated iterations
- Operations in map and reduces steps work best if simple and uniform across a stage
- Repository
- Repository manages central state across multiple running processes
- Processes access and update their own and central state through predefined communications mechanisms
- Need to ensure that two processes don’t have access to same data simutaneously
- Pipelines/Workflows
- Pipelines can manage multiple synchronous or asynchronous processing steps in a linear fashion
- Each step can have its own logic
- Workflows are similar to pipelines but are more complex interactions and can be represented as Directed Acyclic Graphs
Serial vs Parallel Code and Flynn’s Taxonomy
- Findiing a value in array.
- Serial search scale with data size
- Parallel search scale with data size and number of threads
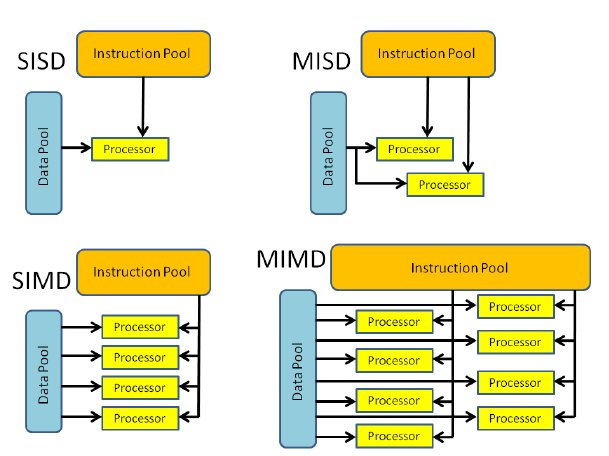
- Flynn’s Taxonomy
Python 3 Parallel Programming Syntax and Patterns
_thread/threadinglibrariesimport _thread/threadingstart_new_thread(function, args[, kwargs])shortcut for run, start, etc.- lock, acquire, and release - initialize synchronization lock and use aquire and release to control access to critical sections of code
- Semaphore objects can be used control like a lock to control access to code, though, with the BoundedSemaphore, multiple threads can acquire up to a specified limit of connections
- Event objects allow communications between threads
- A Barrier can be used to synchronize multiple threads to points in code that are no thread can continue until all threads have become parties to the barrier.
asyncioLibrary - Basic Syntaximport asyncio import time async def say_after(delay, what): await asyncio.sleep(delay) print(what) async def main(): print(f"started at {time.strftime('%X')}") await say_after(1, "hello") await say_after(2, "world") print(f"finished at {time.strftime('%X')}") asyncio.run(main())asyncioLibrary - Advanced Syntaximport asyncio async def async_func1(): return 42 async def async_func2(): return 6*7 async def main(): task = asyncio.create_task(async_func1()) await task await asyncio.gather(async_func1(), async_func2()) await asyncio.sleep(1) asyncio.run(main())multiprocessingLibrary - Basic Syntax- Similar to threading library, except that unlike threads, processes can exist outside of python environment, allowing processes to continue beyond current context and even remotely.
spawn,fork,forkserver- start methods provide different context to created processesprocess,start,join- initialization methods and starting and ending to processesQueueandPipe- two types of interprocess communications mechanismsLock,acquire,release- Create and use synch lock between multiple processes
multiprocessingLibrary - Data SharingValueandArray- share memory objects between processesPool- Pool objects allow for managing multiple workers, a common pattern to offload processing as it is needed- This library implements the synchronization primitives (beyond the Locks) like those in threading, including Barrier, Semaphore, and Event objects
C++ Parallel Programming Syntax and Patterns
std::threadstd::thread thread1 (function)- create thread with function, function pointer or lambda as only argumentthread1.join- synchronizes thread1 on completion of functionthread1.detach- detaches thread1 from control by calling thread
std::mutexstd::mutex.lock()- locks access to critical section of codestd::mutex.try_lock()- if mutext is not locked, this will lock current section, otherwise the function will continue and disregard the locked section of codestd::mutex.unlock()- releases lock on critical section of code
std::atomic- Any atomic-typed is guaranteed to not cause a race condition
atomickeyword is used to delcare a variable atomic- Most C++ primitives (bool, integer-based numbers, pointers and size_t) have an atomic variant
atomic_thread_fence- used to create fence for access to atomic value, use parametermemory_order_acquireandmemory_order_releaseas with acquire/release
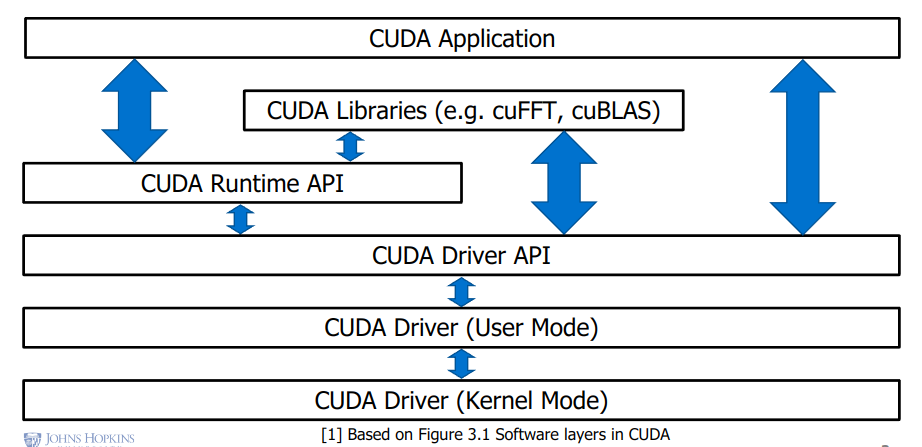
std::futurestd::promise- create a promise, used to wrap around the result of an operation, accessible when that operation is completedstd::future- when valid, allows for retrieving a value from a provider. In conjunction with a promise, will synchronize access to the results of a function call when completedstd::async- calls a function asynchronously. Use withwaitandgetCuda Software Layers
- Cuda software layers
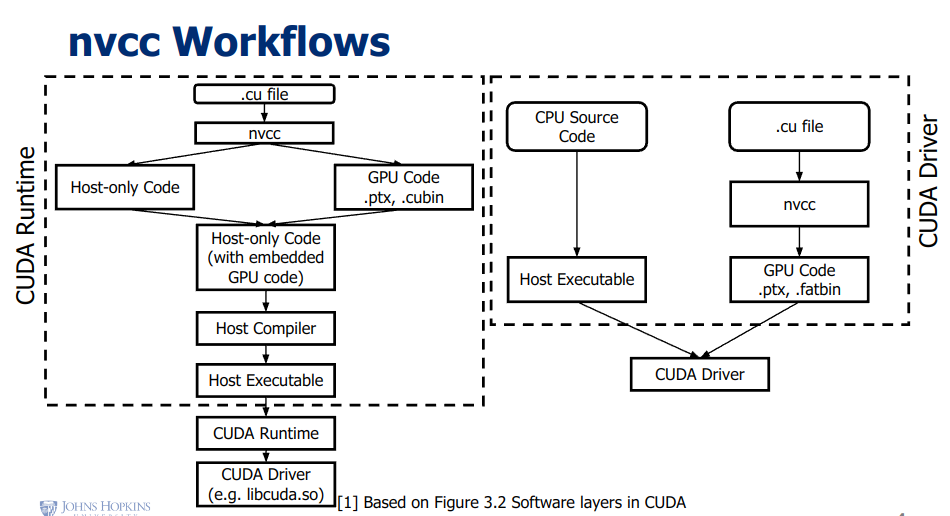
- nvcc workflow
Cuda Code Compilation Example
```bash
outputting a .ptx file
nvcc hello-world.cu -o hello-world –ptx
targeting a specific virtual architecture
nvcc hello-world.cu -o hello-world –arch sm_62
### Cuda Runtime API vs Cuda Driver API
1. Runtime API
+ A simpler option than the driver api
+ Removes the need for keeping track of contexts, certain forms of initialization and management of modules
+ No need to load specific kernels as all available kernels are initialized on program start
2. Driver API
+ Allow more fine grain control of what is executed on hardware
+ Any base that can invoke `cubin` objects will be able to use this code
+ The Driver API needs to be initialized at least once via the `cuInit` function
+ Will need to manage devices, modules and contexts
### Compilation and Execution Steps
1. Runtime API code example
```cpp
__global__ void vector_add(float *out, float *a, float*b, int n) {
for (int i = 0; i < n; ++i) {
out[i] = a[i] + b[i];
}
}
#define N 10000000
int main() {
// allocate pointer memory
float *a, *b, *out, *d_a, *d_b, *d_out;
a = (float*)malloc(sizeof(float) * N);
// initialize arrays
for (int i = 0; i < N; ++i){
a[i] = 1.0f;
b[i] = 2.0f;
}
// copy data to GPU
cudaMemcpy(d_a, a, sizeof(float) * N, cudaMemcpyHostToDevice);
// execute the kernel
vector_add<<<1, 1>>>(d_out, d_a, d_N);
// copy from GPU
cudaMemcpy(out, out_d, sizeof(float)*N, cudaMemcpyDeviceToHost);
// Deallocate
cudaFree(d_a);
}
- Runtime API code compilation
nvcc runtime_example.cpp -o runtime_example -lcuda - Driver API code example ```cpp extern “C” global void matSum(int *a, int *b, int *c) { int tid = blockIdx.x; if (tid < N) c[tid] = a[tid] + b[tid]; }
int main(int argc, char **argv) { // set up CUfunction matrixSum = NULL; int block_size = 32; initCUDA(argc, argv, &matrixSum);
// host memory allocation initialization
const float valB = 0.01f;
constantInit(h_B, size_B, valB);
// device memory allocation
CUdeviceptr d_A;
checkCudaErrors(cuMemAlloc(&d_A, mem_size_A));
// copy
checkCudaErrors(cuMemcpyHtoD(d_A,h_A, mem_size_A));
// run kernel
void *args[5] = {&d_C, &d_A, &d_B, &Matrix_Width_A, &Matrix_Width_B};
checkCudaErrors(cuLaunchKernel(matrixMul, grid.x, grid.y, grid.z, block.x, block.y, block.z, 2*block_size*block_size*sizeof(float), NULL, args, NULL));
// deallocate
free(h_A);
cuMemFree(d_A); }
static int initCUDA(int argc, char **argv, CUfunction *pMatrixMul) { // get device and device info cuDevice = findCudaDeviceDRV(argc, (const char **)argv); cuDeviceGetAttribute(&major, CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MAJOR, cuDevice); cuDeviceGetAttribute(&minor, CU_DEVICE_ATTRIBUTE_COMPUTE_CAPABILITY_MINOR, cuDevice); cuDeviceGetName(deviceName, sizeof(deviceName), cuDevice);
// create context from device
cuCtxCreate(&cuContext, 0, cuDevice);
// retrieve CUDA function from module on PATH
std::string module_path;
std::ostringstream fatbin;
CUfunction cuFunction = 0;
checkCudaErrors(cuModuleLoadData(&cuModule, fatbin.str().c_str()));
checkCudaErrors(cuModuleGetFunction(&cuFunction, cuModule, "matrixMul_bs32_64bit"));
*pMatrixMul = cuFunction;
return 0; } ``` 4. Driver API code compilation ```bash nvcc driver_example_kernel.cu -o driver_example_kernel.fatbin -fatbin
nvcc driver_example.cpp -o driver_example -lcuda ```
CUDA Keywords
- Execution / Invocation Keywords
__device__called from GPU context from and executed on GPU__global__called from CPU context from and executed on GPU__host__called from CPU context from and executed on CPU
- Threads, Blocks, and Grids
kernel<<<blocksPerGrid, threadsPerBlock, sizeOfSharedMemory(optional), cudaStream(optional)>>>(kernelArgs)- Threads - each invocation of a kernel function executes on a single thread
- Blocks - collections of threads that share memory and need to be a multiple of 32
- Grids - collections of blocks that share some memory
- Memory Keywords
int,char,float, etc - based on the hardware and number of threads registers will be used.const/__constant__- constant memory keyword, will attempt to allocate based on hardwareshared/__shared__- like constant keyword, but memory is shared within a block__device__- optionally indicates that device memories are intended for GPU