Encoding and Evolution
Changes
In most cases, a change to an application’s features also requires a change to data that it stores.
- Relational databases generally assume that all data in the database conforms to one schema: although that schema can be changed (through schema migrations; i.e., ALTER statements), there is exactly one schema in force at any one point in time.
- By contrast, schema-on-read (“schemaless”) databases don’t enforce a schema, so the database can contain a mixture of older and newer data formats written at different times.
When a data format or schema changes, a corresponding change to application code often needs to happen.
- With server-side applications you may want to perform a rolling upgrade (also known as a staged rollout), deploying the new version to a few nodes at a time.
- With client-side applications you’re at the mercy of the user, who may not install the update for some time.
we need to maintain compatibility in both directions
- Backward compatibility - Newer code can read data that was written by older code.
- Forward compatibility - Older code can read data that was written by newer code.
Formats for Encoding Data
- In memory, data is kept in objects, which are optimized for efficient access and manipulation by the CPU (typically using pointers).
- When you want to write data to a file or send it over the network, you have to encode it as some kind of self-contained sequence of bytes.
- The translation from the in-memory representation to a byte sequence is called encoding (also known as serialization or marshalling), and the reverse is called decoding (parsing, deserialization, unmarshalling)
Language-Specific Formats
it’s generally a bad idea to use your language’s built-in encoding for anything other than very transient purposes
- pickle in python, marshal in ruby, java.io.serializable in Java
- The encoding is often tied to a particular programming language, and reading the data in another language is very difficult.
- In order to restore data in the same object types, the decoding process needs to be able to instantiate arbitrary classes. This is frequently a source of security problems.
- Versioning data and efficiency is often an afterthought in these libraries.
JSON, XML, and Binary Variants
- XML is often criticized for being too verbose and unnecessarily complicated.
- JSON’s popularity is mainly due to its built-in support in web browsers and simplicity relative to XML.
- CSV is another popular language-independent format, albeit less powerful.
Problems:
- There is a lot of ambiguity around the encoding of numbers.
- JSON and XML have good support for Unicode character strings (i.e., human readable text), but they don’t support binary strings.
- XML and JSON have schema support, they are powerful but complicated, and many don’t use schema.
- CSV does not have any schema.
Binary encoding
- JSON is less verbose than XML, but both still use a lot of space compared to binary formats.
- This observation led to the development of a profusion of binary encodings for JSON (MessagePack, BSON, BJSON, UBJSON, BISON, and Smile, to name a few) and for XML (WBXML and Fast Infoset, for example).
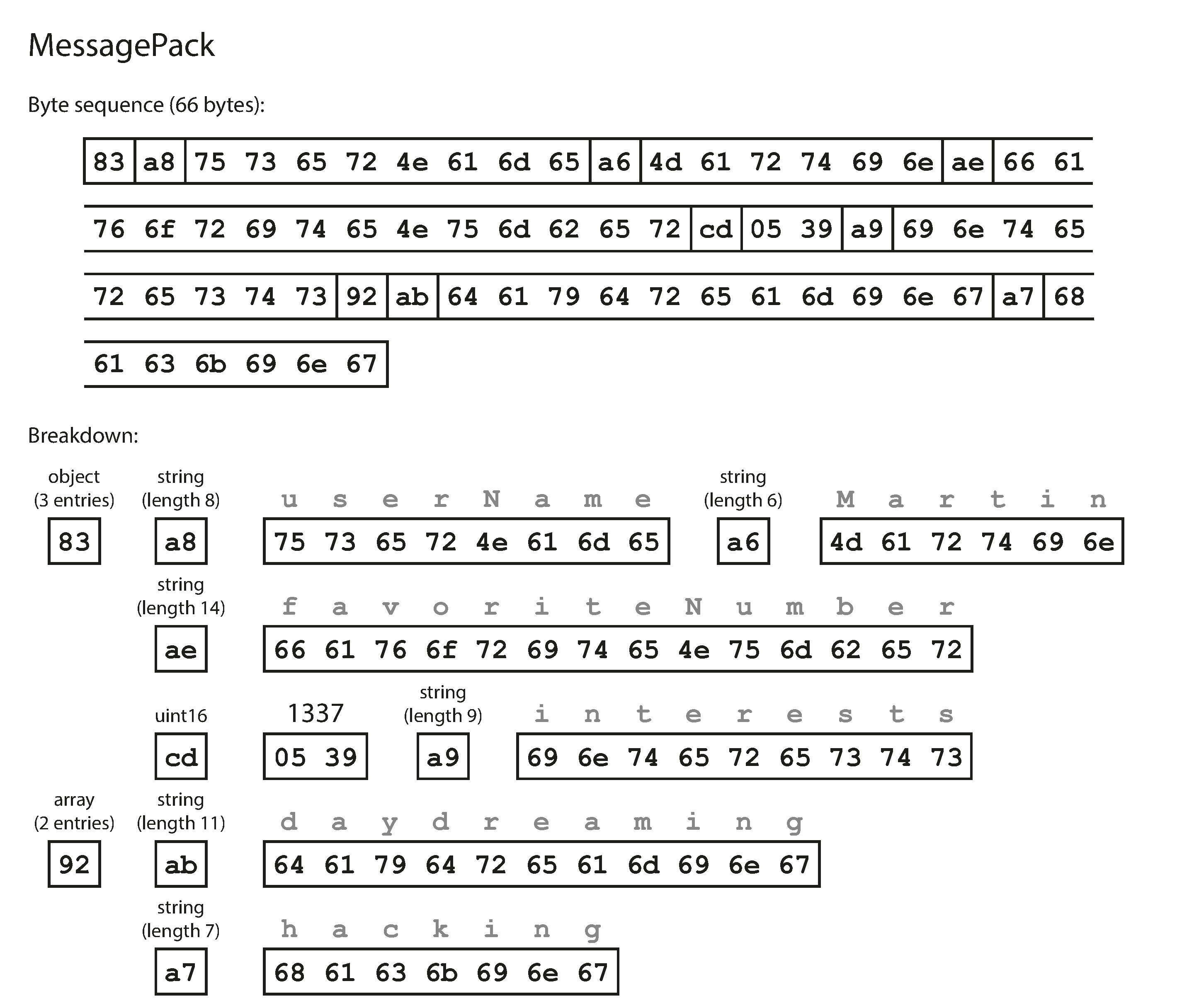
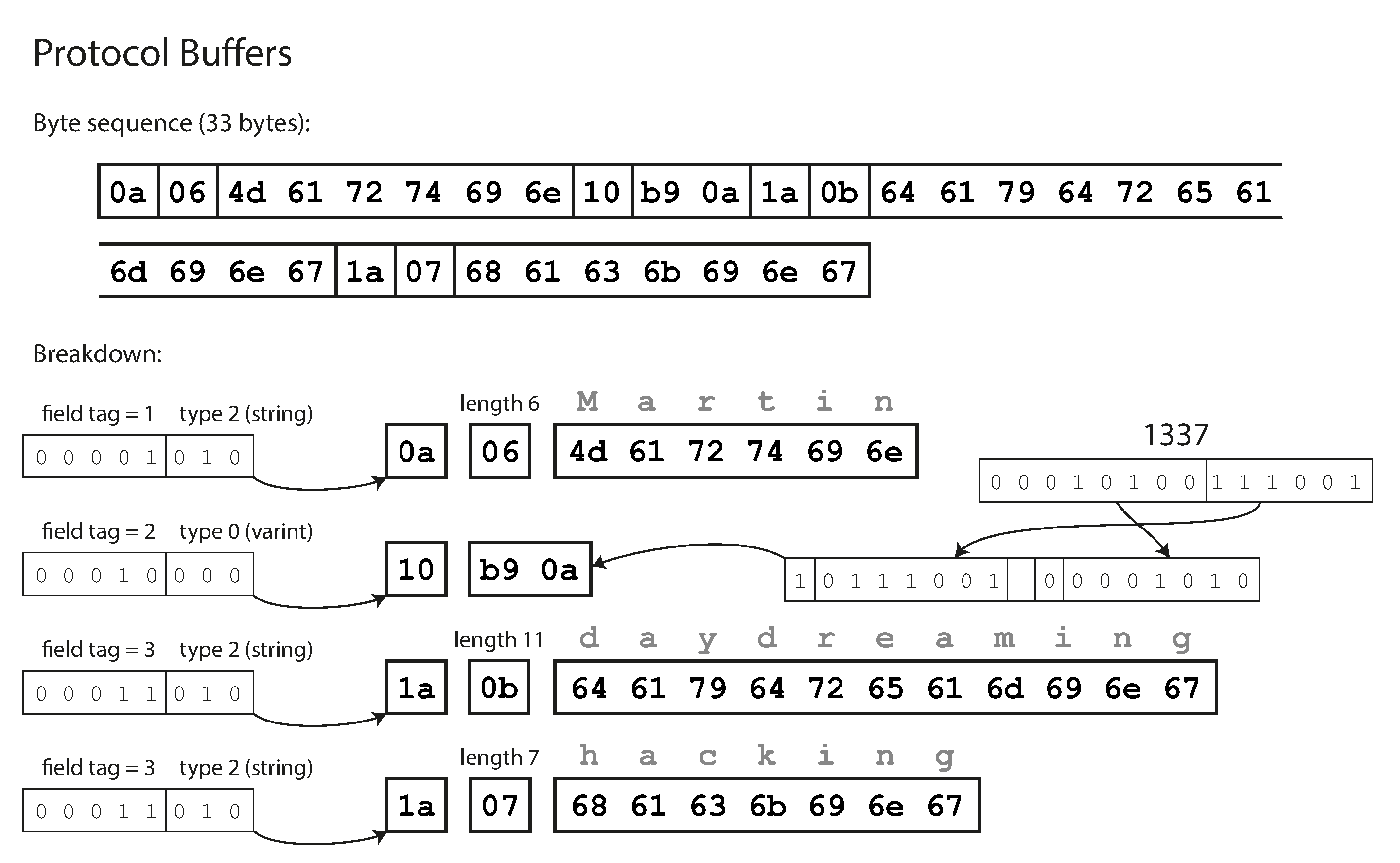
Thrift and Protocol Buffers
- Apache Thrift and Protocol Buffers (protobuf) are binary encoding libraries that are based on the same principle.
- Protocol Buffers was originally developed at Google,
- Thrift was originally developed at Facebook
- They have interface definition language (IDL) to define schema of the data.
- They have code generation tool to convert the schema definition into class definitions in programming languages.
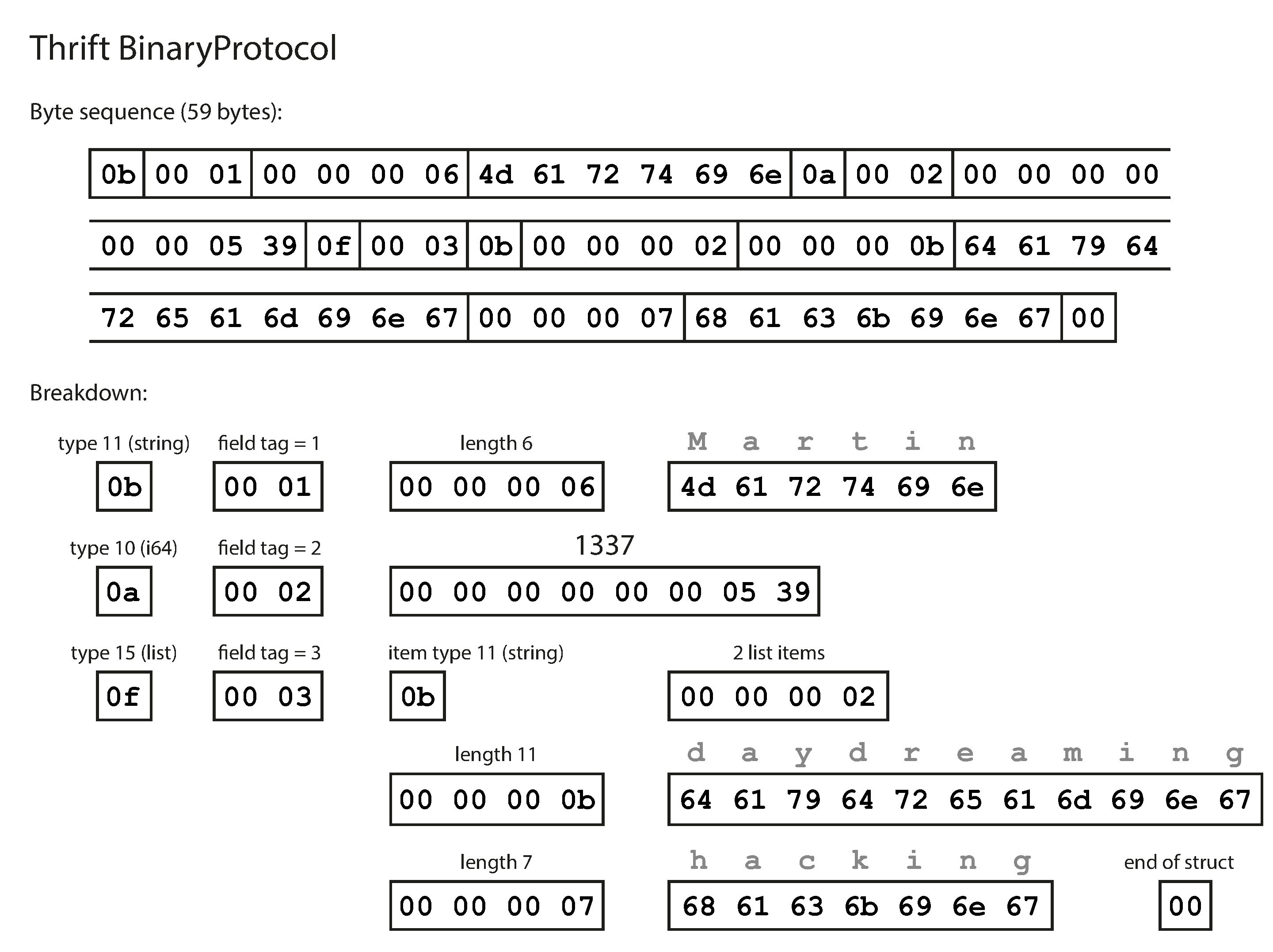
The big difference compared to messagepack is that there are no field names. Instead, the encoded data contains field tags which can be found in the schema definition.
Field tags and schema evolution
- You can add new fields to the schema, provided that you give each field a new tag number.
- old code can simply ignore that field. This maintains forward compatibility: old code can read records that were written by new code.
- For backward compatibility, as long as each field has a unique tag number, new code can always read old data, because the tag numbers still have the same meaning.
- every field you add after the initial deployment of the schema must be optional or have a default value.
Datatypes and schema evolution
That may be possible—check the documentation for details—but there is a risk that values will lose precision or get truncated.
Avro
- Avro also uses a schema to specify the structure of the data being encoded. It has two schema languages: one (Avro IDL) intended for human editing, and one (based on JSON) that is more easily machine-readable.
An example schema def in avro.
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}
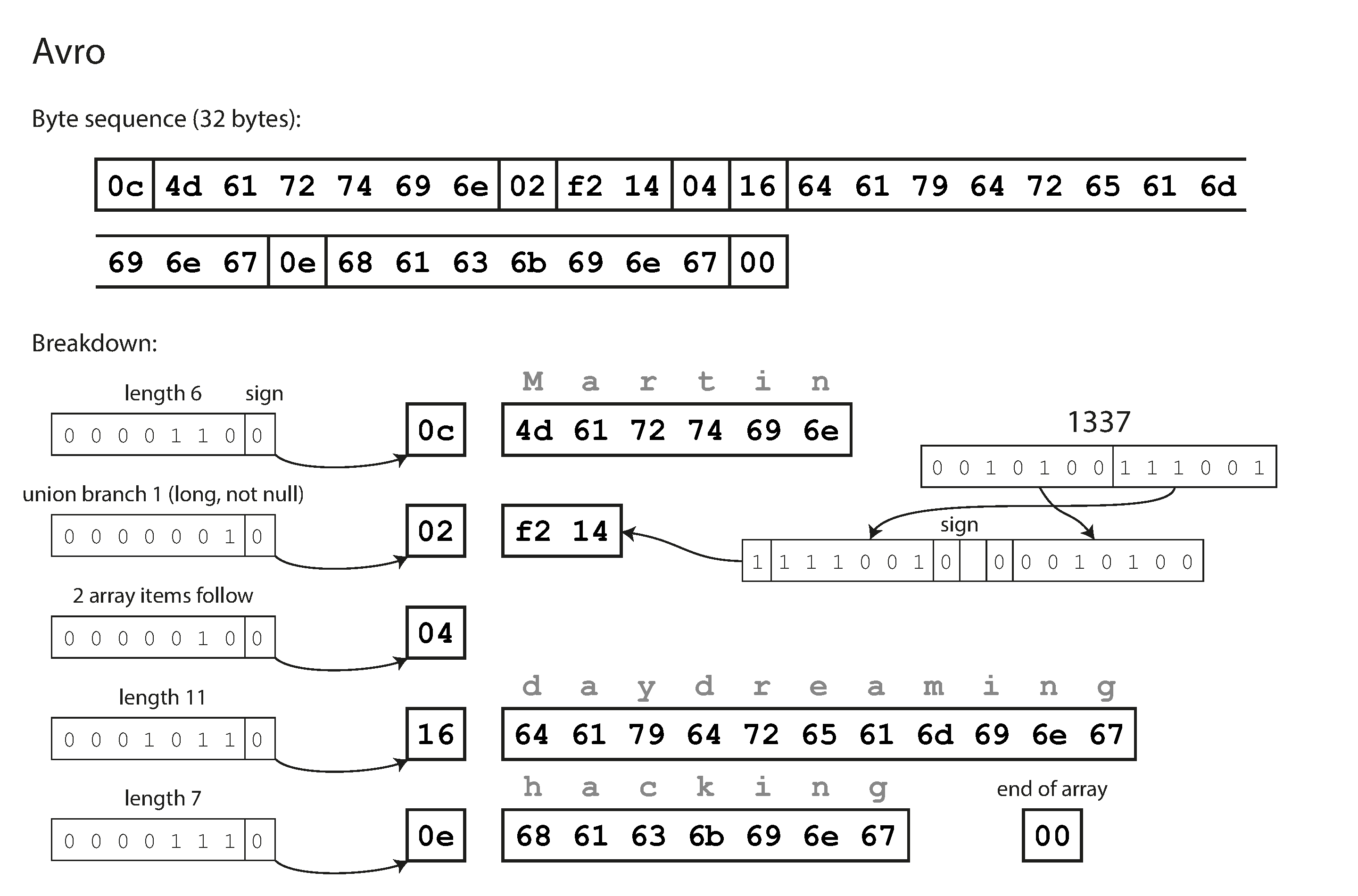
- To parse the binary data, you go through the fields in the order that they appear in the schema and use the schema to tell you the datatype of each field. This means that the binary data can only be decoded correctly if the code reading the data is using the exact same schema as the code that wrote the data. Any mismatch in the schema between the reader and the writer would mean incorrectly decoded data.
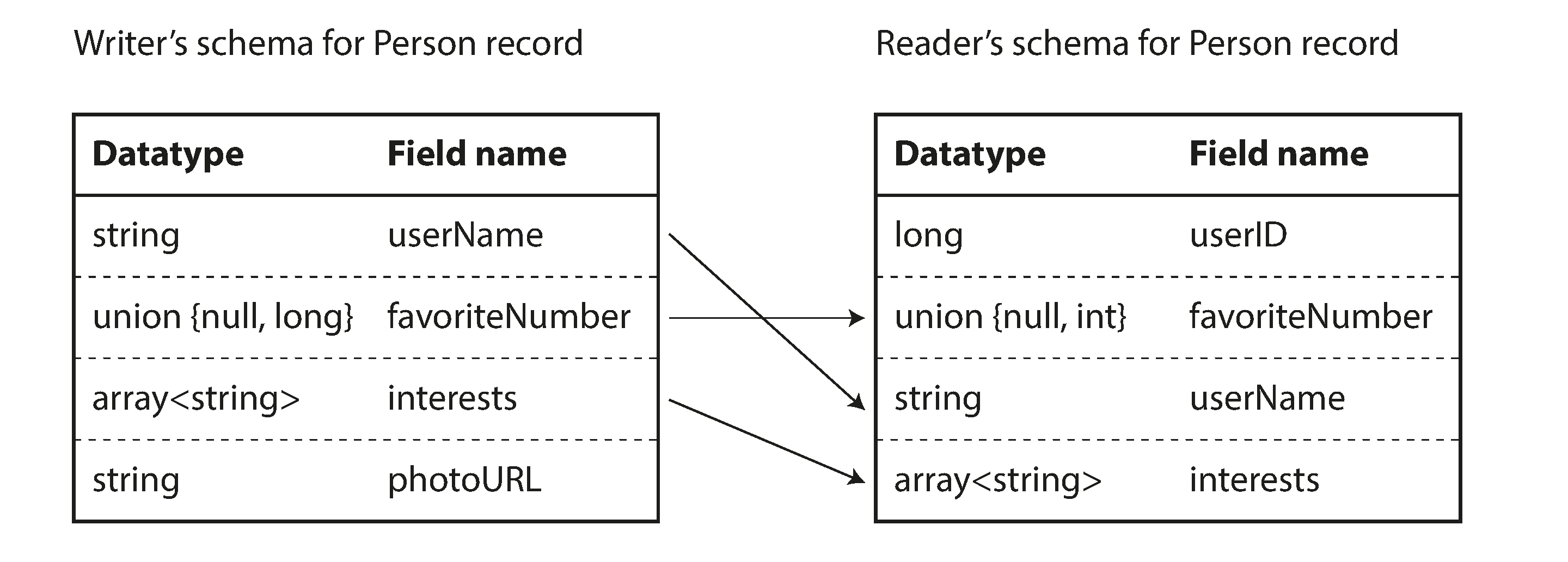
The writer’s schema and the reader’s schema
With Avro, when an application wants to encode some data (to write it to a file or database, to send it over the network, etc.), it encodes the data using whatever version of the schema it knows about—for example, that schema may be compiled into the application. This is known as the writer’s schema.
When an application wants to decode some data (read it from a file or database, receive it from the network, etc.), it is expecting the data to be in some schema, which is known as the reader’s schema.
The key idea with Avro is that the writer’s schema and the reader’s schema don’t have to be the same—they only need to be compatible.
If the code reading the data expects some field, but the writer’s schema does not contain a field of that name, it is filled in with a default value declared in the reader’s schema.
Schema evolution rules
- With Avro, forward compatibility means that you can have a new version of the schema as writer and an old version of the schema as reader.
- Conversely, backward compatibility means that you can have a new version of the schema as reader and an old version as writer.
- To maintain compatibility, you may only add or remove a field that has a default value.
- If you were to add a field that has no default value, new readers wouldn’t be able to read data written by old writers, so you would break backward compatibility.
-
If you were to remove a field that has no default value, old readers wouldn’t be able to read data written by new writers, so you would break forward compatibility.
- in Avro: if you want to allow a field to be
null, you have to use auniontype. For example,union { null, long, string } field; indicates that field can be a number, or a string, or null.
writer’s schema
- Large file with lots of records
- A common use for Avro—especially in the context of Hadoop—is for storing a large file containing millions of records, all encoded with the same schema.
- In this case, the writer of that file can just include the writer’s schema once at the beginning of the file.
- Avro specifies a file format (object container files) to do this.
- Database with individually written records
- The simplest solution is to include a version number at the beginning of every encoded record, and to keep a list of schema versions in your data‐base.
- Sending records over a network connection
- When two processes are communicating over a bidirectional network connection, they can negotiate the schema version on connection setup and then use that schema for the lifetime of the connection. The Avro RPC protocol works like this.
Dynamically generated schemas
Avro is friendlier to dynamically generated schemas.
Say you have a relational database whose contents you want to dump to a file, and you want to use a binary format to avoid the aforementioned problems with textual formats (JSON, CSV, SQL). If you use Avro, you can fairly easily generate an Avro schema from the relational schema and encode the database contents using that schema, dumping it all to an Avro object container file.
You generate a record schema for each database table, and each column becomes a field in that record. The column name in the database maps to the field name in Avro.
If the database schema changes (for example, a table has one column added and one column removed), you can just generate a new Avro schema from the updated database schema and export data in the new Avro schema. Anyone who reads the new data files will see that the fields of the record have changed, but since the fields are identified by name, the updated writer’s schema can still be matched up with the old reader’s schema
Code generation and dynamically typed languages
Avro provides optional code generation for statically typed programming languages, but it can be used just as well without any code generation.
If you have an object container file (which embeds the writer’s schema), you can simply open it using the Avro library and look at the data in the same way as you could look at a JSON file. The file is self-describing since it includes all the necessary metadata.
Modes of Dataflow
- Via databases
- Via service calls
- Via asynchronous message passing
Dataflow Through Databases
In a database, the process that writes to the database encodes the data, and the process that reads from the database decodes it.
think of storing something in the database as sending a message to your future self.
-
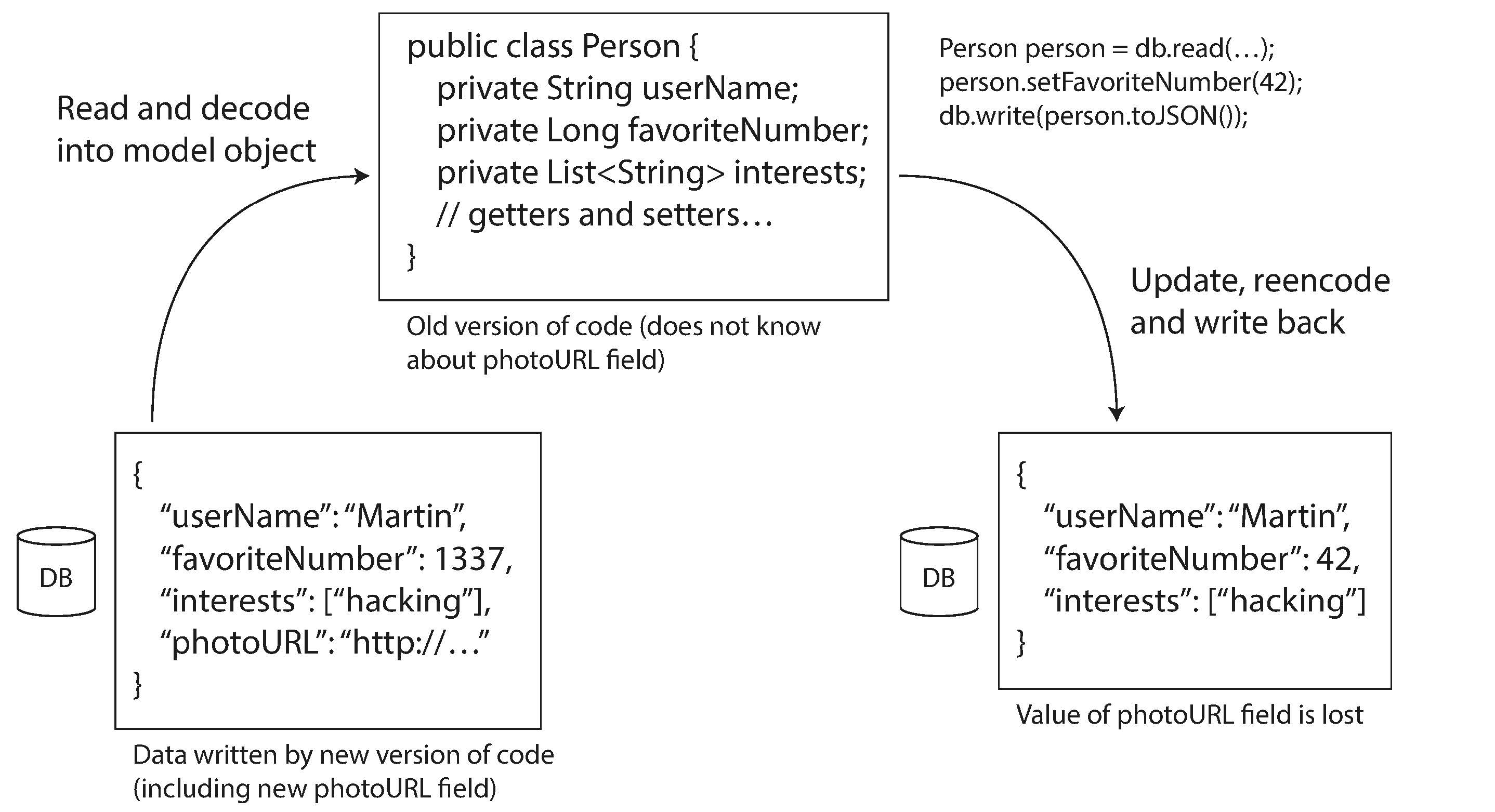
Backward compatibility is clearly necessary here; otherwise your future self won’t be able to decode what you previously wrote.
-
A value in the database may be written by a newer version of the code, and subsequently read by an older version of the code that is still running. Thus, forward compatibility is also often required for databases.
Different values written at different times
- data outlives code: data writen with old schema and never updated ever since.
- Rewriting (migrating) data into a new schema is certainly possible, but it’s an expensive thing to do on a large dataset, so most databases avoid it if possible.
Dataflow Through Services: REST and RPC
Clients and servers:
- The servers expose an API over the network, and the clients can connect to the servers to make requests to that API. The API exposed by the server is known as a service.
- A server can itself be a client to another service (webapp server acts as client to a database).
SOA and Microservices:
- decompose a large application into smaller services by area of functionality, such that one service makes a request to another when it requires some functionality or data from that other service.
- This a service oriented architecture (SOA), more recently refined and rebranded as microservices architecture.
- A key design goal of a service-oriented/microservices architecture is to make the application easier to change and maintain by making services independently deployable and evolvable.
- Services expose an application-specific API that only allows inputs and outputs that are predetermined by the business logic (application code) of the service.
- This restriction provides a degree of encapsulation: services can impose fine-grained restrictions on what clients can and cannot do.
Web services: When HTTP is used as the underlying protocol for talking to the service, it is called a web service. There are two popular approaches to web services: REST and SOAP.
REST
- REST is not a protocol, but rather a design philosophy that builds upon the principles of HTTP. It emphasizes simple data formats, using URLs for identifying resources and using HTTP features for cache control, authentication, and content type negotiation.
- An API designed according to the principles of REST is called RESTful.
- RESTful APIs tend to favor simpler approaches, typically involving less code generation and automated tooling. A definition format such as OpenAPI, also known as Swagger, can be used to describe RESTful APIs and produce documentation.
SOAP
- SOAP is an XML-based protocol for making network API requests.
- The API of a SOAP web service is described using an XML-based language called the Web Services Description Language, or WSDL.
- WSDL enables code generation so that a client can access a remote service using local classes and method calls (which are encoded to XML messages and decoded again by the framework)
The problems with remote procedure calls (RPCs)
- The RPC model tries to make a request to a remote network service look the same as calling a function or method in your programming language, within the same process (this abstraction is called location transparency).
- Examples: Enterprise JavaBeans(EJB), Java’s Remote Methods Invocation(RMI), Distributed Component Object Model(DCOM), Common Object Request Broker Architecture(COBRA).
- A network request is very different from a local function call, that is why old RPC approaches are flawed
Current directions for RPC
- Thrift and Avro come with RPC support included, gRPC is an RPC implementation using Protocol Buffers.
- This new generation of RPC frameworks is more explicit about the fact that a remote request is different from a local function call.
Custom RPC protocols with a binary encoding format can achieve better performance than something generic like JSON over REST. However, a RESTful API has other significant advantages: it is good for experimentation and debugging.
Data encoding and evolution for RPC
- Thrift, gRPC(protocol buffers) and Avro RPC use their respective encoding format.
- SOAP uses XML
- REST uses JSON
Message-Passing Dataflow
asynchronous message-passing systems are somewhere between RPC and databases.
- They are similar to RPC in that a client’s request (usually called a message) is delivered to another process with low latency.
- They are similar to databases in that the message is not sent via a direct network connection, but goes via an intermediary called a message broker (also called a message queue or message-oriented middleware), which stores the message temporarily.
- It can act as a buffer if the recipient is unavailable or overloaded, and thus improve system reliability.
- It can automatically redeliver messages to a process that has crashed, and thus prevent messages from being lost.
- It avoids the sender needing to know the IP address and port number of the recipient (which is particularly useful in a cloud deployment where virtual machines often come and go).
- It allows one message to be sent to several recipients.
- It logically decouples the sender from the recipient (the sender just publishes messages and doesn’t care who consumes them).
message-passing communication is usually one-way:
- a sender normally doesn’t expect to receive a reply to its messages.
- It is possible for a process to send a response, but this would usually be done on a separate channel.
- This communication pattern is asynchronous: the sender doesn’t wait for the message to be delivered, but simply sends it and then forgets about it.
Message brokers
- TIBCO, IBM WebSphere, webMethods
- RabbitMQ, ActiveMQ, HornetQ, NATS, Apache Kafka
in general, message brokers are used as follows:
- one process sends a message to a named queue or topic, and the broker ensures that the message is delivered to one or more consumers of or subscribers to that queue or topic.
- There can be many producers and many consumers on the same topic.
- A topic provides only one-way dataflow.
- However, a consumer may itself publish messages to another topic (so you can chain them together), or to a reply queue that is consumed by the sender of the original message (allowing a request/response dataflow, similar to RPC).
- Message brokers typically don’t enforce any particular data model.
Distributed actor frameworks
A distributed actor framework essentially integrates a message broker and the actor programming model into a single framework.