Random Notes
Some random paper reading notes.
LLM (large language models)
-
Jeff Dean fun fact: Jeff co-authored a paper in 2007 titled “large language models in machine translation” with LLM be a 5-gram model trained on 1500 machines for about 1 day.
- Emergent Abilities of LLMs: abilities that are not present in smaller-scale models but are present in large-scale models
- In-context learning.
- prompt LLM with natural language instructions and/or examples, it can generate expected output for the test instance.
- some propose that in-context learning implicitly performs meta-optimization through the attention mechanism.
- Instruction following.
- LLM finetuned on large multitask natural language instructions datasets can understand new instructions not present in the training data.
- Step-by-step reasoning.
- Solve complex problems by prompt the LLM to reason in steps.
- Obtained with code data?
- In-context learning.
- Are Emergent Abilities of Large Language Models a Mirage?
- The ‘Emergent Abilities of LLMs’ might be an artifact of flawed evaluation.
- Evaluation metrics are nonlinear or discontinuous compared to per token error rate.
- Evaluation data too small or not sufficient
- The ‘Emergent Abilities of LLMs’ might be an artifact of flawed evaluation.
Architecture
- encoder-decoder - very few LLMs are encoder-decoder
- decoder only
- casual decoder - uni-directional attention mask - most LLMs
- prefix decoder - bi-directtional attention over prefix, uni-directional attention on generated tokens. - GLM
ST-MoE Barret Z. et al.
- ST MoE stands for stable and transferable Mixture of Experts
-
269B params ST MoE encoder-decoder transformer has computational cost comparable to a 32B dense conterpart.
- Sparse expert model: use a router or gating network to determine where(what expert sub network) to send inputs.
- Router/Gating: \(h(x) = W_r \cdot x\) then go through softmax to produce gate value for experts.
- Shazeer et al. 2017 for each token x route it to top-k experts and aggregates outputs
- Fedus et al. 2021 reduce to top-1.
- expert capacity factor: number of tokens can be routed to each expert. overflow tokens will be passed to next layer via residual connections.
- load balancing loss: an auxiliary loss to encourge each group of tokens to evenly distrubute across experts.
- treatment for instability in training sparse models:
router-z loss: penalizes large logits into the gating network
- recommendations
- top-2 routing with 1.25 capacity factor
- can change capacity factor during evaluation (like train with 1.25 CF eval with 2CF)
- observations:
- sparse models are prone to overfit
- encoder experts exhibit specialization
- decoder experts lack specialization
Infrastructure
Pathways Barham P. et al.
- gross tl,dr: Jax backend for extremely large language models
Learning/Training/Tuning
Language Models are Few-Shot Learners Brown et al. 2020
- There are sometimes repeated sub-tasks embedded within a single sequence in the unsupervised pre-training data. Model picked up the ability to condition on the input-output task examples in the input sequence to better perform on task without parameter updates.
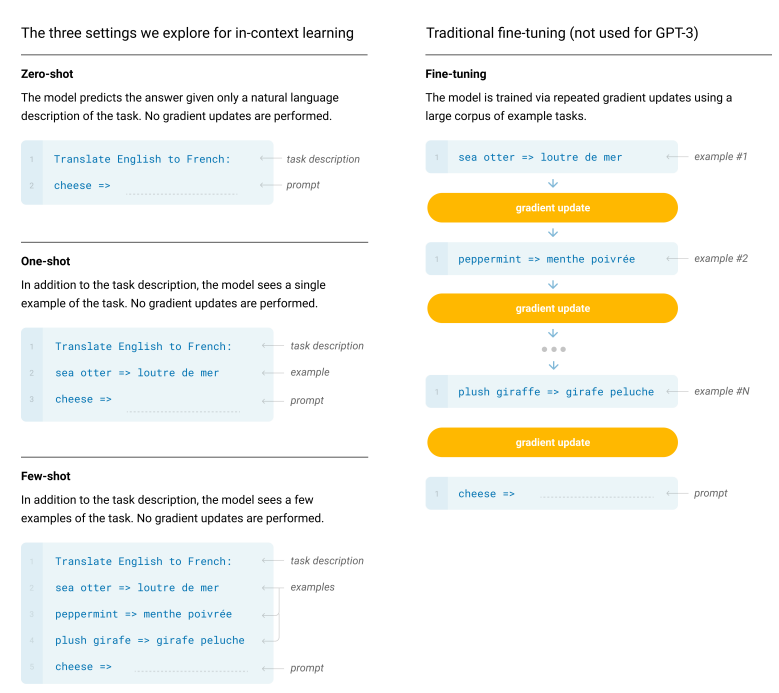
Finetuned Language Models Are Zero-Shot Learners Wei J. et al 2021
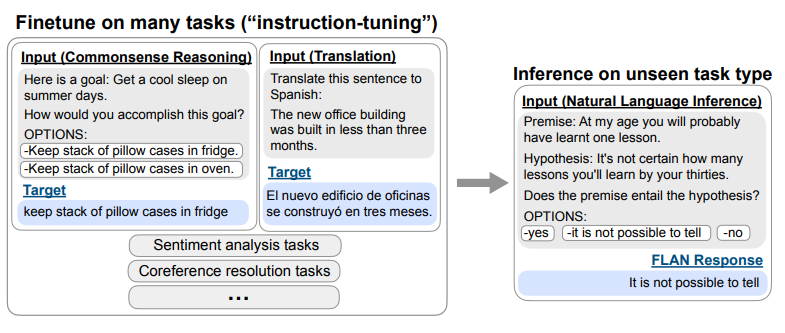
Scaling Instruction-Finetuned Language Models Chung H. et al
- Instruction finetuning does scale well with the nubmer of tasks and the size of the model.
- Finetuning with chain-of-thought helps.

What Makes In-Context Learning Work? Min Sewon et al.
Title seems too broad consider limited task type and datasets in the study.
- Finding:
- In classification task setup, ground truth in the demostrations has only a marginal effect.
- Model may adapt to the input and label distribution and the format suggested by the demostration, but it may also ignore the demostration.
- Hypothesis:
- Demostrations or instructions prompt helps model recover the capacity it already has, but do not supervise the model to learn noval task semantics.
We argue that contrary to the common interpretation of the few-shot format implied by the title of the original GPT-3 paper, Language models are few-shot learners, GPT-3 is often not actually learning the task during run time from few-shot examples. Rather than instruction, the method’s primary function is task location in the model’s existing space of learned tasks. Reynolds and McDonell
Instruct GPT Long O. et al
- LLM model pre-training objective, ie. filling the blank, differs from the end user objective “follow the user’s instructions helpfully and safely”. The two are misaligned.
- Approach this misalignment with fine-tuning model with reinforcement learning from human feedback.
In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3.
- Labelers significantly prefer InstructGPT outputs over outputs from GPT-3. (Well it is fined tuned with labeler’s data, and further fined tuned with labler’s preference model!)
- InstructGPT models show improvements in truthfulness over GPT-3. (In closed domain problems, hallucinaion rate cut in half.)
- Small improvement in toxicity but not bias.
- Observed performance regression on benchmarks after this finetune.
- Show promising generalization to instructions outside of the RLHF fine-tunning distribution.
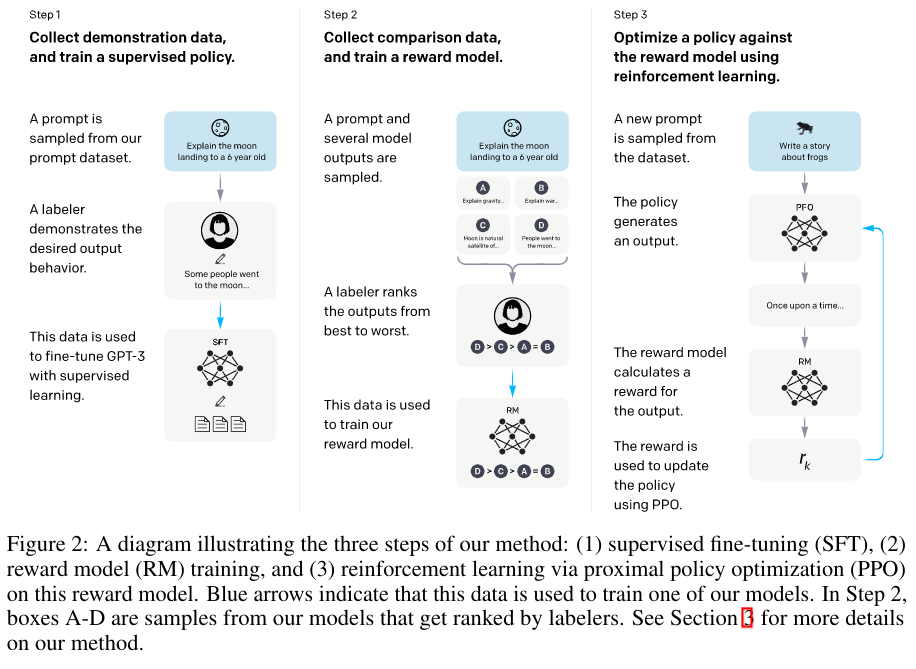
Inference
Chain-of-Thought Prompting Wei J. et al.
chain-of-thought prompting improves performance on a range of arithmetic, common sense, and symbolic reasoning task.
- A chain of thought is a series of intermediate natural language reasoning steps that lead to the final output.
- Given a prompt that consists of triples:
<input, chain of thought, output>followed by real input, ask model to generate reasoning and output.
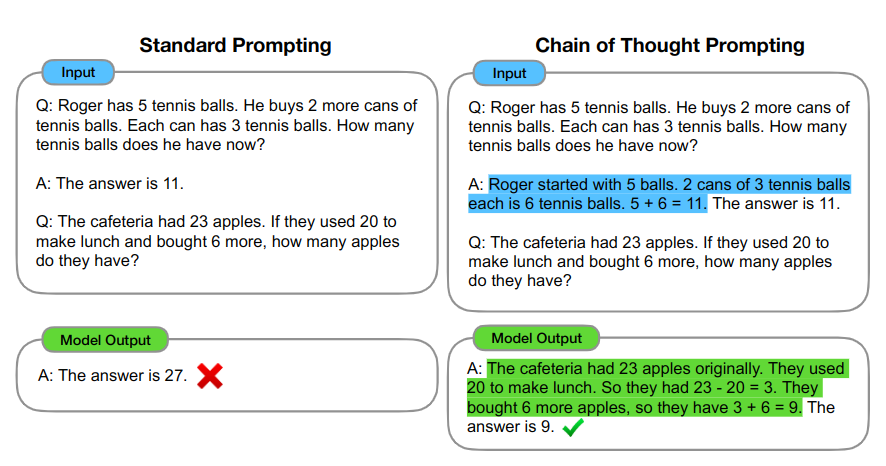
Some high-level takeaway:
- chain-of-thought prompting hurts performace for most models smaller than 10B.
- chain-of-thought prompting gives larger performance gains for larger models.
- chain-of-thought prompting has larger performance gains for more-complicated problems.
Will chain-of-thought prompting helps my task?
- Can human benefit from using chain-of-thought reasoning to solve the problem? If so, go to 2.
- Can we use large models? If so, go to 3.
- By scaling model sizes up, is the scaling curve flat? i.e. task does not gets much easier for larger models.
Scaling
Scaling up transformer based LLMs has been the major way to improve models:
- scaling up model size, (ie. depth and width, sparse activations)
- scaling up tokens model is trained on
- scaling up data sources, quality and tasks
PaLM Chowdhery A. et al.
- Scaling up GPT style decoder only model size to 540B and data size to 780B tokens, trained on Pathways backend to have good FLOPS utilization
- Many small model architecture details: activation, parallel layer, multi-query attention, RoPE embedding, no biases etc.
- Many training details: weight initialization, optimizer, loss, hyperparameter, batch size etc.
- Observed loss spikes even with gradient clipping, restart from previous checkpoint and skip some batches of data.
Jordan H. et al.
we find that for compute-optimal training, the model size and the number of training tokens should be scaled equally: for every doubling of model size the numberof training tokens should also be doubled
- Chinchilla - samller Gopher trained with more tokens under the same compute budget, outperforms Gopher uniformally among downstream tasks.
- Gopher - 280B params 300B tokens vs Chinchilla - 70B params 1.4T tokens.
Abbrevation, Terms and Concepts
| Abbreviation | Meaning |
|---|---|
| RLHF | Reinforcement learning from human feedback |
| Concept | Meaning |
|---|---|
| in-contex learning | Large language model performs a task just by conditioning on input-output examples, without optimizing any parameters |